1.提出问题
之前一直在做深度学习的遥感分类问题,目前的深度学习技术还是属于强监督学习,过分依赖数据。因此,想着在传统的机器学习方面做一些探索,之前也用过一些ENVI等软件做过类似于最大似然法、SVM等方法的遥感影像提取,但知其表不知其意。因此,此次通过自己动手来学习整个数据处理和代码的流程。
2.解决问题
完全从底层来写随机森林比较耗时间,因此主要是利用python的sklearn库来进行项目的编写。
整个项目也借鉴了该研究内容:python实现随机森林遥感图像分类
3.具体步骤
-
随机森林方法同样属于有监督的学习,因此,需要做一些标签,也就是特征工程。这里我们选取ArcGIS去做标签。
(1)在菜单栏空白处右键点选,选择“Image Classification”功能,如下:
(2)绘制标签,具体步骤如下:
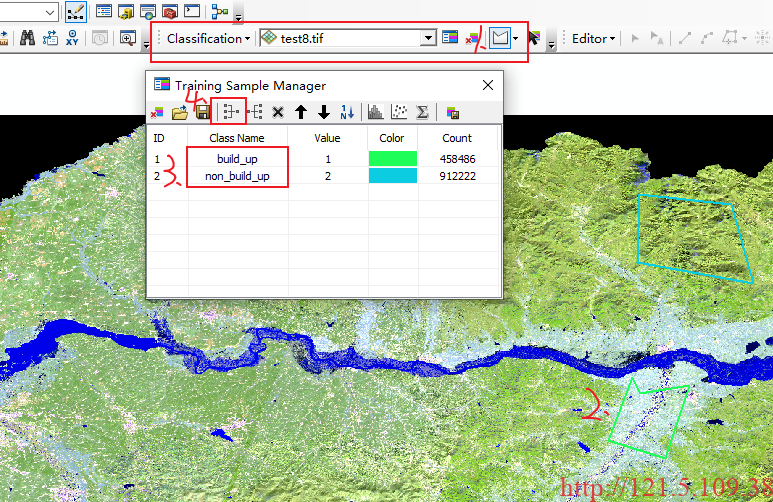
以上第一步骤,选取多边形绘制方式,第二步骤矢量绘制多边形,第三步骤可修改类别名称,第四步骤合并多个要素为同一类别。完成以上步骤,可保存为最终shpfile文件格式。最终通过矢量转栅格形式获得最终掩膜,如下,为全黑图像(实际数值为0和1),放入ArcGIS可直观展示。

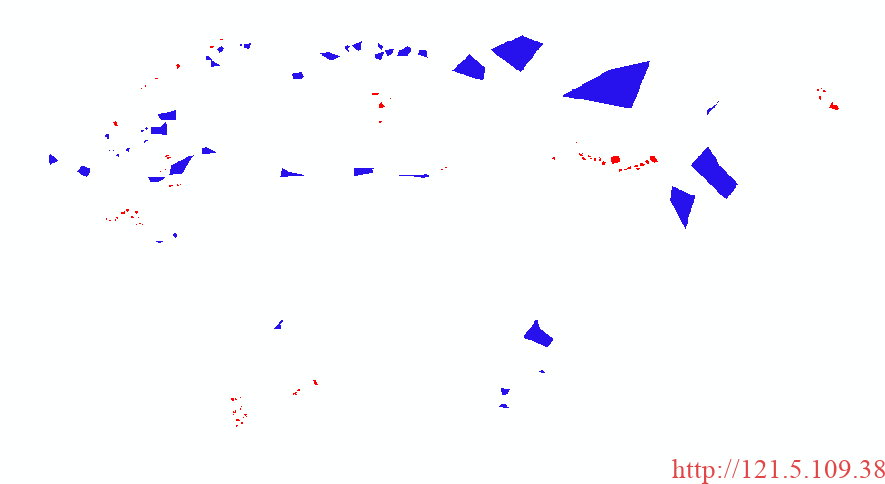
-
利用python的sklearn库进行分类
(1)数据集格式转换
经过上述的栅格形式的掩膜设计,需要构建sklearn库能够直接调用的数据形式,一般为.txt形式。
代码如下:
from osgeo import gdal
import os
import random
#读取tif数据集
def readTif(fileName):
dataset = gdal.Open(fileName)
if dataset == None:
print(fileName+"文件无法打开")
return dataset
Landset_Path = "./data/Landsat8_harbin.tif"
LabelPath = "./data/test81_one_hot.tif"
txt_Path = "./data/label_data.txt"
########################################################## 读取图像数据
dataset = readTif(Landset_Path)
Tif_width = dataset.RasterXSize #栅格矩阵的列数
Tif_height = dataset.RasterYSize #栅格矩阵的行数
Tif_bands = dataset.RasterCount #波段数
print (Tif_bands)
Tif_geotrans = dataset.GetGeoTransform()#获取仿射矩阵信息
Landset_data = dataset.ReadAsArray(0,0,Tif_width,Tif_height)
dataset = readTif(LabelPath)
Label_data = dataset.ReadAsArray(0,0,Tif_width,Tif_height)
# 写之前,先检验文件是否存在,存在就删掉
if os.path.exists(txt_Path):
os.remove(txt_Path)
# 以写的方式打开文件,如果文件不存在,就会自动创建
file_write_obj = open(txt_Path, 'w')
####################################################首先收集建成区类别样本,
####################################################遍历所有像素值,
####################################################为建成区的像元全部收集。
count = 0
for i in range(Label_data.shape[0]):
for j in range(Label_data.shape[1]):
# 设置的建成区在标签图中像元值为0
if(Label_data[i][j] == 0):
var = ""
for k in range(Landset_data.shape[0]):
var = var + str(Landset_data[k][i][j])+","
var = var + "build_up"
file_write_obj.writelines(var)
file_write_obj.write('\n')
count = count + 1
####################################################其次收集非建成区样本,
####################################################因为非建成区样本比建成区样本多很多,
####################################################所以采用在所有非建成区类别中随机选择非建成区样本,
####################################################数量与建成区样本数量保持一致。
Threshold = count
count = 0
for i in range(10000000000):
X_random = random.randint(0,Label_data.shape[0]-1)
Y_random = random.randint(0,Label_data.shape[1]-1)
# 设置的非建成区在标签图中像元值为1
if(Label_data[X_random][Y_random] == 1):
var = ""
for k in range(Landset_data.shape[0]):
var = var + str(Landset_data[k][X_random][Y_random])+","
var = var + "non_build_up"
file_write_obj.writelines(var)
file_write_obj.write('\n')
count = count + 1
if(count == Threshold):
break
file_write_obj.close()运行结果如下:
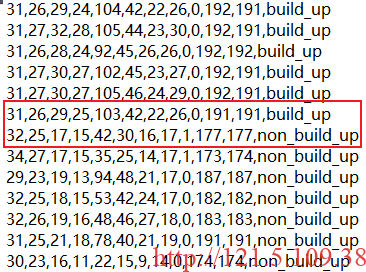
以上代码得到该运行结果,其中每一行前11个数字表示Landsat8影像每个波段对应像素的像素值,也就是我们后续作为输入的11个特征。最后的第12列为类别,我们这里主要为“build_up”和“non_build_up”两大类,为二分类任务。
(2)模型训练
代码如下:
from sklearn.ensemble import RandomForestClassifier
import numpy as np
from sklearn import model_selection
import pickle
import sklearn.ensemble as ensemble
# 直接使用交叉网格搜索来优化决策树模型,边训练边优化
from sklearn.model_selection import GridSearchCV
# 定义字典,便于来解析样本数据集txt
def Iris_label(s):
it={b'build_up':0, b'non_build_up':1}
return it[s]
path="../data/label_data.txt"
SavePath = "../data/model.pickle"
# 1.读取数据集
data=np.loadtxt(path, dtype=float, delimiter=',', converters={11:Iris_label} )
# converters={11:Iris_label}中“11”指的是第12列:将第12列的str转化为label(number)
# 2.划分数据与标签
x,y=np.split(data,indices_or_sections=(11,),axis=1) #x为数据,y为标签
x=x[:,0:11] #选取前11个波段作为特征
train_data,test_data,train_label,test_label = model_selection.train_test_split(x,y, random_state=1, train_size=0.9,test_size=0.1)
# 3.用多个树来创建随机森林模型,训练随机森林
# 一样是直接使用网格搜索
param_grid = {
'criterion':['entropy','gini'],
'max_depth':[5, 6, 7, 8], # 深度:这里是森林中每棵决策树的深度
'n_estimators':[11,13,15], # 决策树个数-随机森林特有参数
'max_features':[0.3,0.4,0.5], # 每棵决策树使用的变量占比-随机森林特有参数(结合原理)
'min_samples_split':[4,8,12,16] # 叶子的最小拆分样本量
}
classifier = ensemble.RandomForestClassifier()
classifier = GridSearchCV(estimator=classifier, param_grid=param_grid,
scoring='roc_auc', cv=4)
classifier.fit(train_data, train_label.ravel())#ravel函数拉伸到一维
# 4.计算随机森林的准确率
print("训练集:",classifier.score(train_data,train_label))
print("测试集:",classifier.score(test_data,test_label))
# 5.保存模型
#以二进制的方式打开文件:
file = open(SavePath, "wb")
#将模型写入文件:
pickle.dump(classifier, file)
#最后关闭文件:
file.close()运行结果:

以上代码运行后,会得到上述形式的模型。
(3)模型预测
代码如下:
import numpy as np
from osgeo import gdal
import pickle
#读取tif数据集
def readTif(fileName):
dataset = gdal.Open(fileName)
if dataset == None:
print(fileName+"文件无法打开")
return dataset
#保存tif文件函数
def writeTiff(im_data,im_geotrans,im_proj,path):
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, im_height, im_width = im_data.shape
#创建文件
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)
if(dataset!= None):
dataset.SetGeoTransform(im_geotrans) #写入仿射变换参数
dataset.SetProjection(im_proj) #写入投影
for i in range(im_bands):
dataset.GetRasterBand(i+1).WriteArray(im_data[i])
del dataset
RFpath = "../data/model.pickle"
Landset_Path = "../data/Landsat8_harbin.tif"
SavePath = "../data/save_result.tif"
dataset = readTif(Landset_Path)
Tif_width = dataset.RasterXSize #栅格矩阵的列数
Tif_height = dataset.RasterYSize #栅格矩阵的行数
Tif_geotrans = dataset.GetGeoTransform()#获取仿射矩阵信息
Tif_proj = dataset.GetProjection()#获取投影信息
Landset_data = dataset.ReadAsArray(0,0,Tif_width,Tif_height)
################################################调用保存好的模型
#以读二进制的方式打开文件
file = open(RFpath, "rb")
#把模型从文件中读取出来
rf_model = pickle.load(file)
#关闭文件
file.close()
################################################用读入的模型进行预测
# 在与测试前要调整一下数据的格式
data = np.zeros((Landset_data.shape[0],Landset_data.shape[1]*Landset_data.shape[2]))
for i in range (Landset_data.shape[0]):
print (i)
data[i] = Landset_data[i].flatten()
data = data.swapaxes(0,1)
# 对调整好格式的数据进行预测
pred = rf_model.predict(data)
print (pred.shape)
# 同样地,对预测好的数据调整为图像的格式
pred = pred.reshape(Landset_data.shape[1],Landset_data.shape[2])*255
pred = pred.astype(np.uint8)
# 将结果写到tif图像里
writeTiff(pred,Tif_geotrans,Tif_proj,SavePath)运行结果:
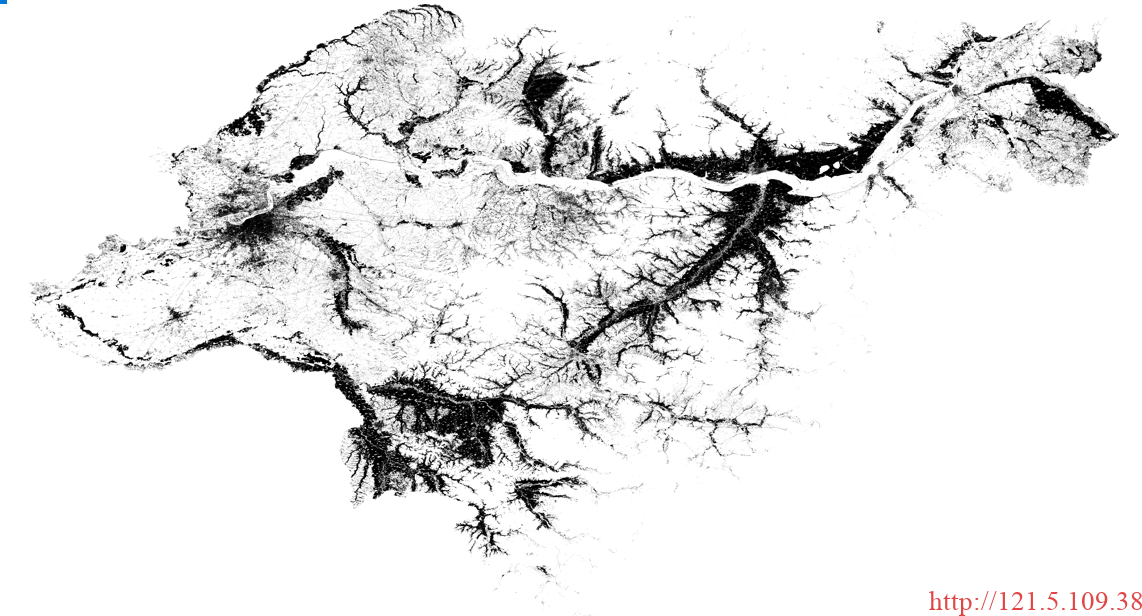
以上为最终分类的结果,黑色为建成区,白色为非建成区。分类结果不一定准确,该结果只是展示效果。(整个代码的运行时间较长,大约为2天左右,一方面是因为数据量大,另一方面是完全用cpu在跑。综上,时间效率确实低一点,后续会尝试看看是否有优化的空间)

文章评论