提出问题
之前的《给定语句提取含有地理信息的省份》一节提出对给定事件提取到了省份,那么如果我们要对其可视化并且做一些统计分析,应该怎么办?
解决思路
利用Pyecharts强大的可视化功能实现简单的前端可视化展示和统计分析
方法
- 之前已通过相关算法提取到省市级别对应的事件发生详情,但是是随机分布的,现在需要对其按省份顺序排列,并且输出为csv表格格式。处理操作如下:
import json
import csv
content = json.load(open("./class.json"))
with open('test.csv', 'a', newline='',encoding='utf-8-sig') as f:
header = ['事件名称', '类型', '发生地', '详情']
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader() # 写入列名
for item in content:
datas = []
datas.append(item)
writer.writerows(datas) # 写入数据处理结果如下:
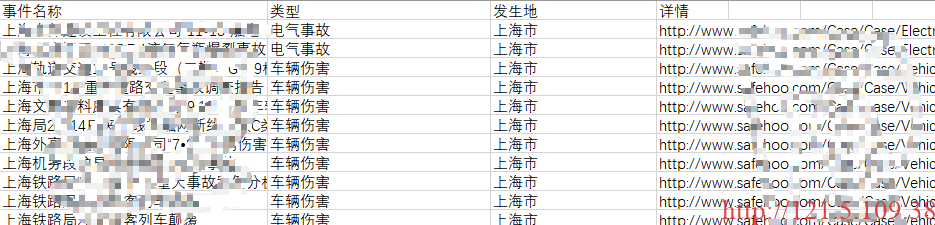
- 进一步将上述结果按省市级别分割成单个csv存储。处理操作如下:
import numpy as np
import pandas as pd
import csv
from collections import defaultdict
path = "./test.csv"
df = pd.read_csv(path, header=0, usecols = [2])
data_array = np.array(df.stack()) # 首先将pandas读取的数据转化为array
data_list = data_array.tolist() # 然后转化为list形式
dd = defaultdict(list)
for k, va in [(v,i) for i, v in enumerate(data_list)]:
dd[k].append(va)
df1 = pd.read_csv(path,header=0)
for i,j in dd.items():
#print (i,j)
if len(j) == 1:
cont_part = df1[j[0]:j[0]+1]
else:
cont_part = df1[j[0]:j[-1]]
cont_part.to_csv("./pro_csv/{}.csv".format(i), index_label = 'ID', encoding='utf-8-sig')处理结果如下:


- 对以上各个省份发生的事件类型进行统计分析。处理操作如下:
# 导入必要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import *
from pyecharts.components import Table
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
import random
import datetime
import warnings
warnings.filterwarnings("ignore")
import os
from collections import defaultdict
def make_html(cate, data, file_name):
pie = (Pie()
.add('', [list(z) for z in zip(cate, data)])
.set_global_opts(tooltip_opts=opts.TooltipOpts(is_show=True,
# 鼠标移动或者点击时触发
trigger_on="mousemove|click",
formatter='{b} :{d}%',
background_color="green",
textstyle_opts=opts.TextStyleOpts(color='red')
))
)
pie.render(file_name + ".html")
files = './pro_csv'
files_html = "./type_html/"
file_list = os.listdir(files)
#type_thing = ["爆炸事故",'车辆事故','电气事故','高处坠落','']
for item in file_list:
df = pd.read_csv(os.path.join(files, item), header=0, usecols = [2])
data_array = np.array(df.stack()) # 首先将pandas读取的数据转化为array
data_list = data_array.tolist() # 然后转化为list形式
dd = defaultdict(list)
for k, va in [(v,i) for i, v in enumerate(data_list)]:
dd[k].append(va)
type_thing = []
count_thing = []
for i, j in dd.items():
count_i = j[-1] - j[0] + 1
type_thing.append(i)
count_thing.append(count_i)
print (item)
print (type_thing)
print (count_thing)
make_html(type_thing, count_thing, files_html + item[:-4])处理结果如下:
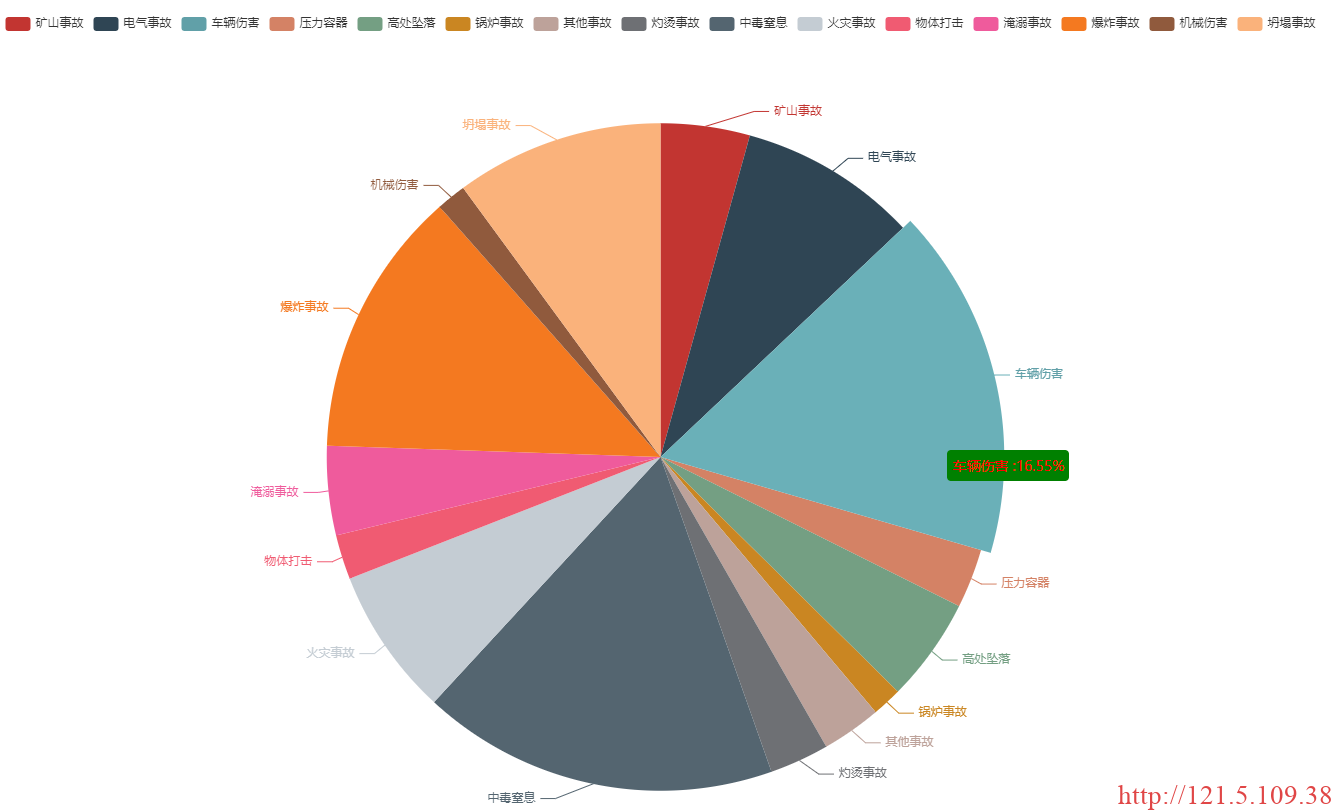
- 再以每个省市级构建全国地图显示,通过地图选择显示相关详细信息。处理操作如下:
#coding=utf-8
import pandas as pd
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import *
from pyecharts.components import Table
from pyecharts.commons.utils import JsCode
from pyecharts.faker import Faker
import os
import numpy as np
from collections import defaultdict
import re
def visulization(list_item):
c = (
Map(init_opts=opts.InitOpts(width="1000px", height="600px")) #初始化地图大小
.set_global_opts(
title_opts=opts.TitleOpts(title="全国事故类型可视化"), #配置标题
visualmap_opts=opts.VisualMapOpts(type_ = "scatter", is_piecewise=True,
pieces=[
{"min":0,"max":3,"label":"0~3","color":"cyan"},
{"min":4,"max":7,"label":"4~7","color":"yellow"},
{"min":8,"max":11,"label":"8~11","color":"orange"},
{"min":12,"max":15,"label":"12~15","color":"coral"},
{"min":16,"max":17,"label":"16~17","color":"red"},
]
)
)
.add("事故种类总数", list_item, maptype="china") #将list传入,地图类型为中国地图
.render("全国事故发生地图.html")
)
files = './pro_csv'
file_list = os.listdir(files)
total_pro = []
total_type = []
for file in file_list:
df1 = pd.read_csv(os.path.join(files, file), header=0, usecols = [2], encoding='utf-8-sig')
df2 = pd.read_csv(os.path.join(files, file), header=0, usecols = [3], encoding='utf-8-sig')
data_array1 = np.array(df1.stack()) # 首先将pandas读取的数据转化为array
data_list1 = data_array1.tolist() # 然后转化为list形式
#print (data_list1)
len_type = len(set(data_list1))
data_array2 = np.array(df2.stack()) # 首先将pandas读取的数据转化为array
data_list2 = data_array2.tolist() # 然后转化为list形式
data_list2 = list(set(data_list2))
for item in data_list2:
item = filter(lambda ch: ch not in '省市自治区回族壮族维吾尔', item)
item = list(item)
item = "".join(item)
total_pro.append(item)
total_type.append(len_type)
#name_translate = dict(zip(Faker.provinces,total_pro))
list_ = [list(z) for z in zip(total_pro, total_type)]
print (list_)
visulization(list_)处理结果如下:
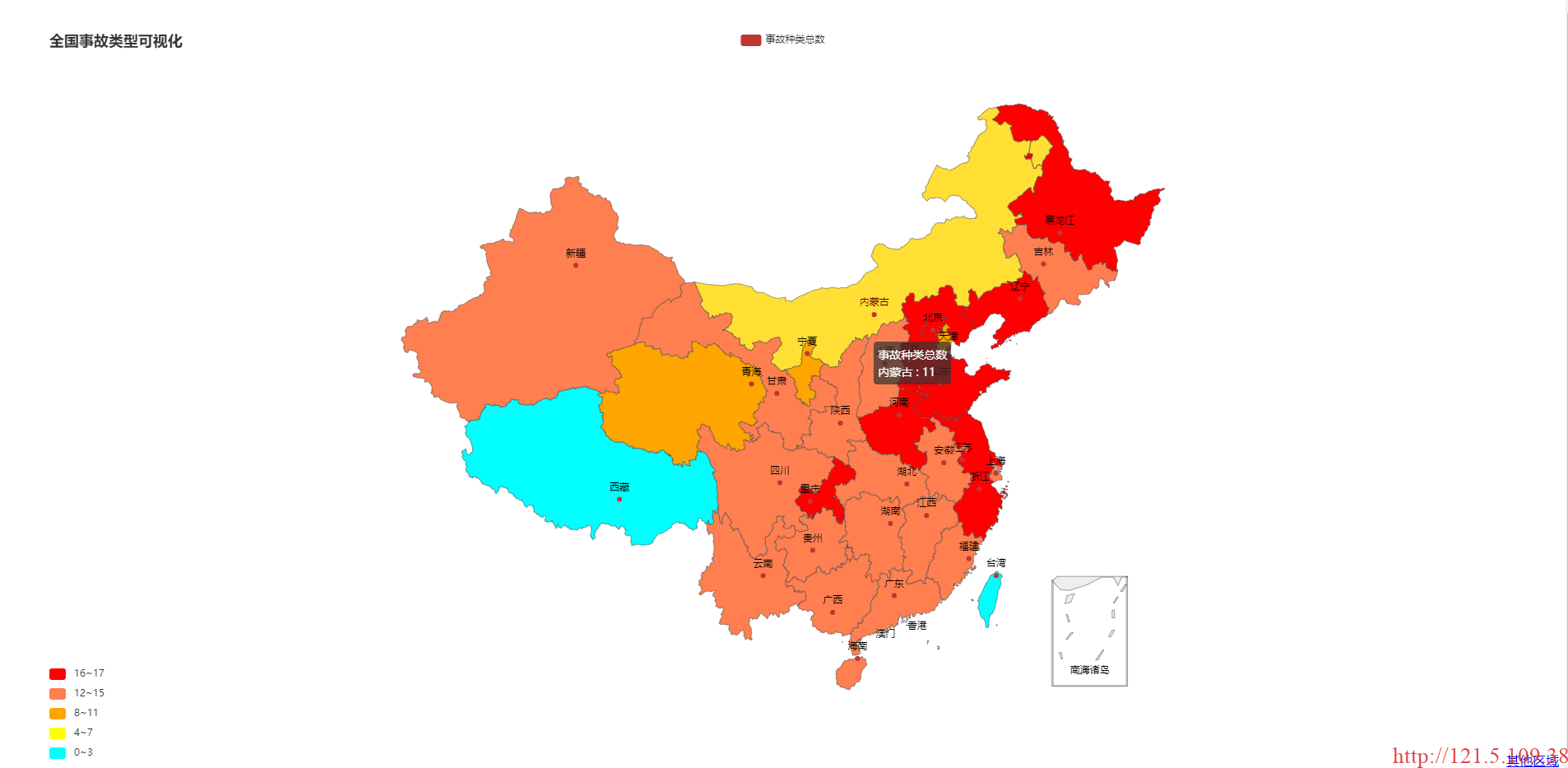
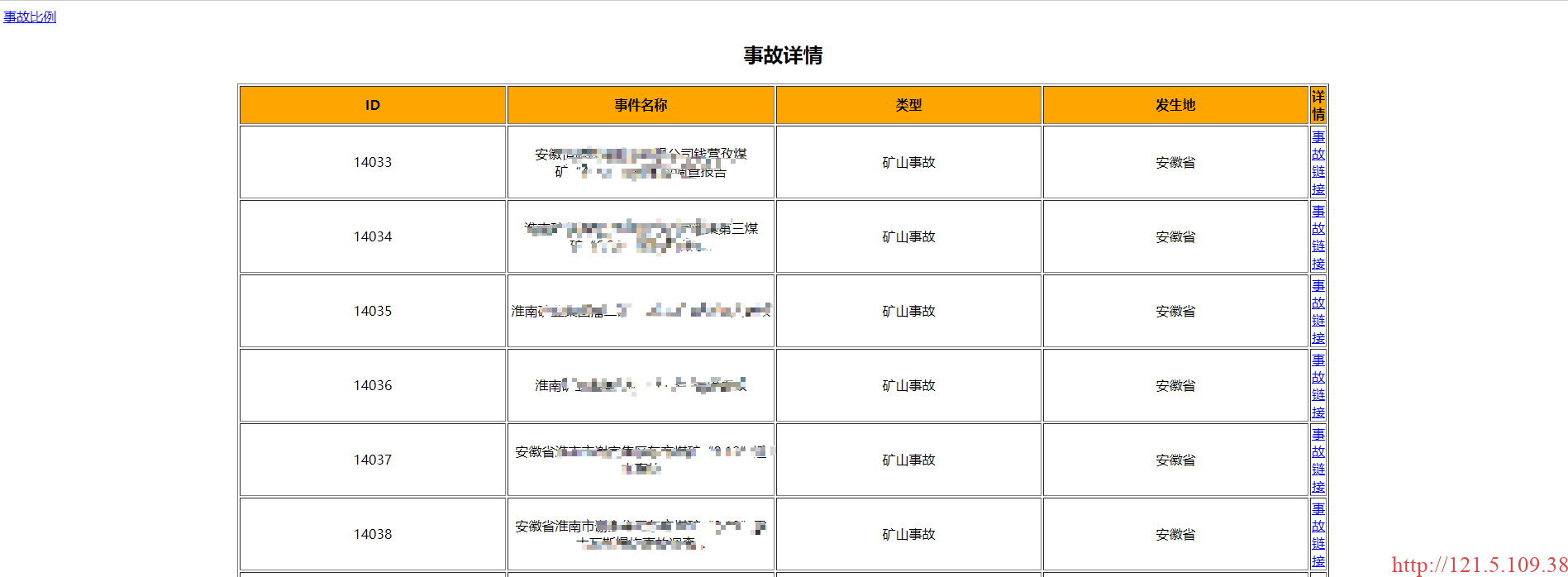
- 将以省市级别单个存储的csv表格以html格式显示,从而实现点击地图可以跳转到html格式显示事件。并且实现了点击生成的事故详情页中的事故比例跳转到第3步生成的对应省市级统计分析图。处理操作如下:
import os
# 填充数据,参数为列表,全部居中显示,返回一个tr
def fill_data(locls1, locls2, locls3, locls4, href_):
seg = '<tr><td align="center">{0}</td><td align="center">{1}</td><td align="center">{2}</td><td align="center">{3}</td><td align="center"><a href={4}>事故链接</a> </td></tr>\n'.format(locls1, locls2, locls3, locls4, href_)
return seg
def csv2html(csv_path, filename):
# 将CSV文件转化为HTML文件
# 标签头
seg1 = '''<!DOCTYPE html><html lang="en"><head>
<meta charset="GBK">
<title>Title</title>
</head>
<body>
<h2 align="center">事故详情</h2>\n
<table border="1" align="center" width="70%">\n
<tr bgcolor="orange">\n'''
# 将数据存入<table>标签中
# 结尾标签
seg2 = "</tr>\n"
seg3 = "</table>\n</body>\n</html>"
seg4 = '<tr><td align="center"><a href={}>事故比例</a></td></tr>'.format('./type_html/' + filename + '.html')
# 获取csv文件,存入列表中
ls = []
with open(csv_path, "r", encoding="utf-8") as fr:
for line in fr:
line = line.replace("\n", "") # 每行去掉换行符
lineout = line.split(",")
ls.append(lineout) # 按分隔符分割
# 写入HTML中
with open("./csv_html/{}.html".format(filename), "w", encoding = 'utf-8-sig') as fw:
fw.write(seg4)
fw.write(seg1)
# 添加表头:ls[0]是表头
fw.write('<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n'.format(*ls[0]))
fw.write(seg2)
# 添加每一行
for i in range(1, len(ls)):
#print (ls[i])
fw.write(fill_data(ls[i][0],ls[i][1],ls[i][2],ls[i][3],ls[i][4]))
# 添加结尾标签
fw.write(seg3)
fw.close()
if __name__ == "__main__":
files_floder = './pro_csv'
files_path = os.listdir(files_floder)
#print(files_path)
for item in files_path:
#print (os.path.join(files_floder, item))
csv2html(os.path.join(files_floder, item), item[:-4])
处理结果如下:

文章评论