Hello,大家好呀!今天来记录一下自己在Ubuntu20.04中进行Docker镜像安装和深度学习框架的过程。
大家都知道使用深度学习的过程中非常依赖于软硬件的配置、环境的搭建。当我们在Linux系统中配置好适用的环境时,有时会和我们需要训练的代码不兼容,难道这时候只能将系统重装、环境重新配置吗?No!No!No!这样会极大的降低咱们学习的效率,增加成本(实际上,就是觉得太麻烦了!毕竟配环境已经很容易Bug百出了)
所以,这个时候咱们只能寻找有没有更简单的方法,最好能把单独的环境打包使用。Docker就很好地解决了这个问题!它能够为我们提供深度学习需要的环境、框架的镜像,帮助我们直接拉取官方已经配好的各种镜像。就像超多类型的“移动套餐”,任君选择。不仅如此,我们还可以在这些“移动套餐”里配备我们想要的各种应用、依赖包等等。
下面就来具体说说,咱们到底需要怎么安装并使用Docker呢?
一、安装Docker
安装Docker的过程很简单,其他网友提供的详细过程就很好。我这里就是参考了热心网友的帖子https://www.cnblogs.com/liang24/p/15230505.html

这个时候就有同学要问了,你这个分享的帖子是Ubuntu18.04安装的过程啦,这怎么行呢?
嘿嘿嘿!大家不要急,我亲身实验过啦,发现安装Docker的过程与Ubuntu版本基本没啥关系。按照这个教程也能安装成功。
二、安装nvidia-docker
由于默认安装的Docker都是基于CPU版本的,如果想要配合GPU进行一些简单的部署的话,则需要安装nvidia-docker来结合使用。当然,前提需要你的硬件支持gpu加速(nvidia系列),同时在系统中已经安装好了nvidia驱动和cuda以及cudnn和docker基础版。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker执行下面命令测试是否安装成功:
docker pull nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04
(这里是安装cuda:11.1。因为我的机子是3090,实践证明,3090更适合11.1以上版本)
然鹅,真的能这么容易吗?我又叒遇到bug了!

分析了一下,应该是docker缺少root权限。解决方法如下:
sudo groupadd docker #添加docker用户组
sudo gpasswd -a $XXX docker #检测当前用户是否已经在docker用户组中,其中XXX为用户名,例如我的,daidai
sudo gpasswd -a $USER docker #将当前用户添加至docker用户组
newgrp docker #更新docker用户组没什么报错,能顺利安装,应该就没啥问题了。
三、Docker 修改容器默认存储位置
为了防止系统盘内存不足,可以修改docker的默认存储路径。
1)查看默认路径:
docker info

2)创建存储路径的文件并编辑
vim /etc/docker/daemon.json
注意:使用vim编辑文本时,按下“i”或者“insert”进行编辑,此时窗体最底部会出现---插入---,即可进行编辑。
3)输入自己修改的存储路径:
{
"graph":"/data/docker"
}4)完成编辑,退出输入,按 ESC 或者‘ctrl+C’,会发现底部的 – INSERT – 没有了
保存并且退出vim编辑
:wq + Enter键
vim保存文件时如果保存不了,强制保存。命令为:
: w ! sudo tee %
然后,使用 :qa! 退出。
到这里,我们就完成一大半儿啦!
四、搭建深度学习环境(重点)
1)从docker hub中找到需要的环境镜像docker hub。这里我选择的是cuda11.1版本配适ubuntu18.04
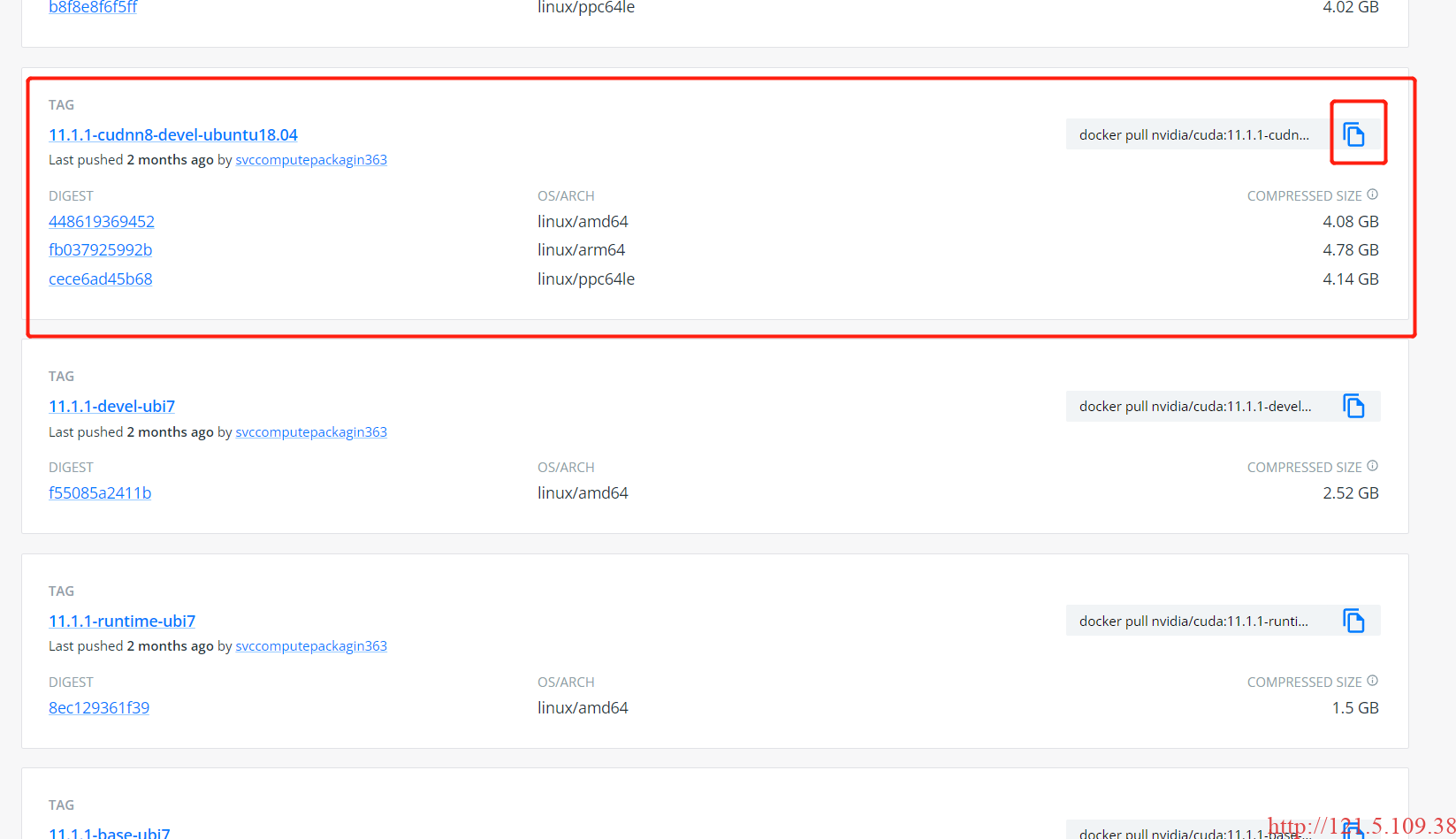
复制 docker pull 命令,在终端拉取镜像
docker pull nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04
2)查看已安装的镜像
docker images

3)通过镜像创建容器,并挂载本地文件夹,文件夹路径根据实际情况写
这里需要注意,可以利用ID或者 “ REPOSITORY:TAG ”来创建容器。
在此之前,我们需要新建一个文件Luojianet,其路径为 /home/daidai/data/zy/DockerContainer/Luojianet ,用作本地与容器之前的连接。然后利用 “/home/daidai/data/zy/DockerContainer/Luojianet:/Luojianet”
将本地的 /home/daidai/data/zy/DockerContainer/Luojianet 路径挂载到容器中的 Luojianet 下。这里就是建立容器与宿主机文件共享(这里将宿主机 Luojianet 文件夹与容器共享,因此代码、数据上传到宿主机 Luojianet 文件夹即可,后续任务基于该文件夹)。注意这个文件夹很重要!!!可以理解为Linux中的home主目录,调用容器之后,使用的路径也是从这个文件夹开始的。
通过ID:
docker run --gpus all --shm-size 8G -it -v /home/daidai/data/zy/DockerContainer/Luojianet:/Luojianet 195963274e92 /bin/bash
通过“ REPOSITORY:TAG ”:
docker run --gpus all -it -v /home/daidai/data/zy/DockerContainer/Luojianet:/Luojianet nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04 /bin/bash
以下就进入创建的容器中了:

注意:我在创建容器的时候出现了一个bug


还好请教了大佬,获得以下解决方法:
sudo find / -name runc
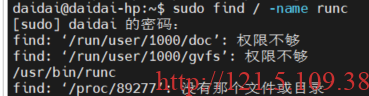
一度以为没有runc!崩溃啊!转念一想,不对啊!我记得明明之前配置主系统的时候有啊?!
然后查看我的NVIDIA驱动,驱动都没了!!!啊啊啊啊!!!怎么会这样!
只能重新安装驱动了。。。心塞啊。查找了一下网上说,也许和软件自动更新有关,所以果断地把它关闭了。祈祷下次驱动还在!!!我安装驱动采用系统推荐的,感觉能少踩雷。
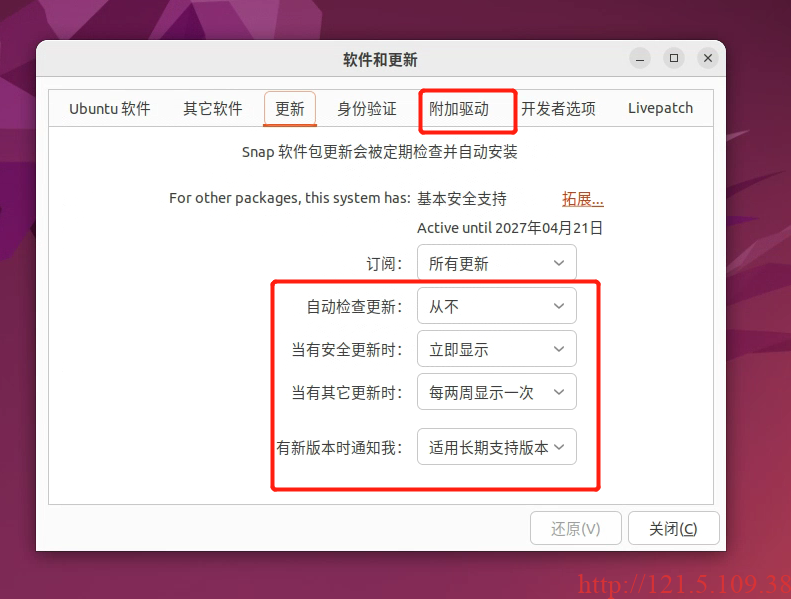
解决完这个问题,再重新创建容器就OK了。
3)检查是否可以调用显卡驱动、cuda是否可用
nvidia-smi
nvcc -V
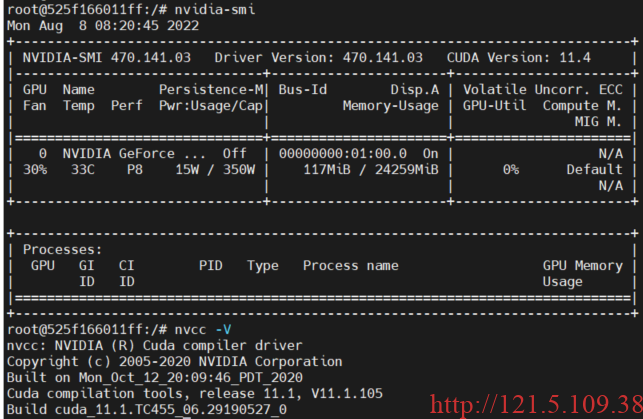
成功配置镜像,并进入容器!!!都没问题,则容器可以成功调用显卡,并使用 cuda!欧耶!
4)安装anaconda
首先,去清华镜像下载我们需要的anaconda版本,这里我用的是 Anaconda3-5.3.0-Linux-x86_64.sh。然后把它上传到之前创建的Luojianet中。
!!!注意!!!
切换到安装包的路径中。由于Loujianet等同于home,因此,切换路劲的时候需要注意,如下:
cd Loujianet
实际上,真实物理机上的路径为/home/daidai/data/zy/DockerContainer/Luojianet。
其实,为了更好的模拟home的使用,可以直接采用home来映射,而无需新建文件夹,即:
/home/daidai/data/zy/DockerContainer/Luojianet:/home/daidai/data/zy/DockerContainer/Luojianet
这样就可以保持和物理机一样的设置了,Luojianet就成了单纯的文件夹,home则为主目录。炒鸡nice啊!
检查并使用conda:
source ~/.bashrc #更新环境变量
source activate #激活conda,进入base环境

文章评论