提出问题
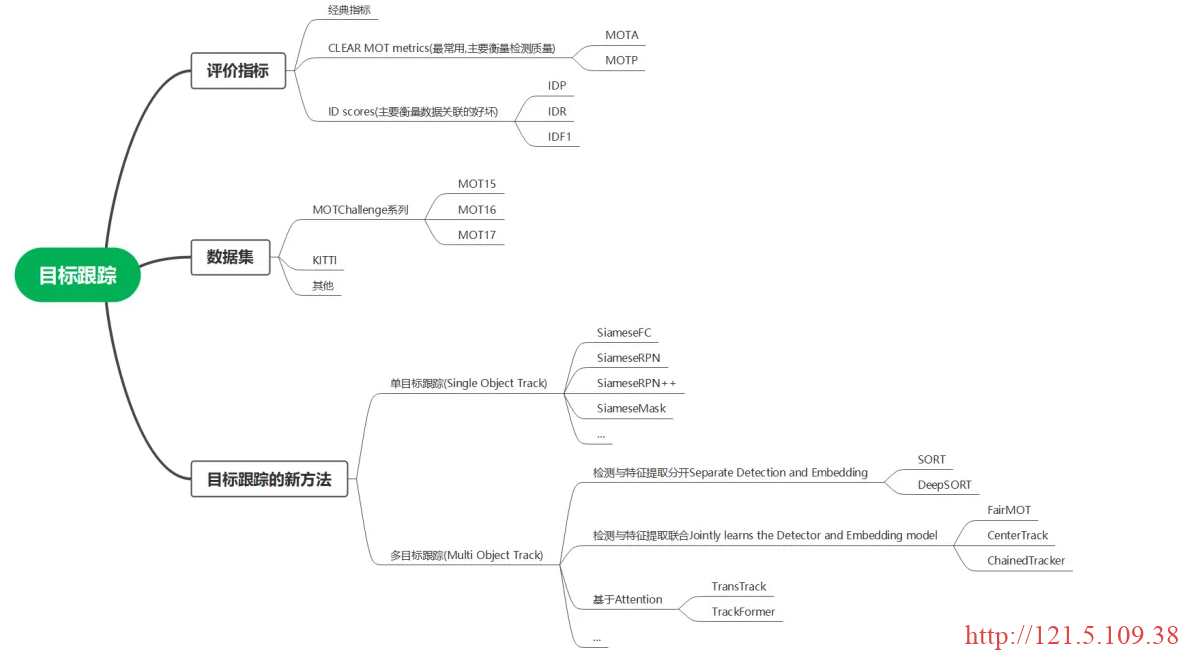
最近因为应用需求,需要实现基于视频的多目标跟踪任务。目标跟踪的发展脉络大体如下图所示,之前虽然做过类似的基于联合检测的目标跟踪,即图中的检测与特征提取联合的方式,如2020年提出的FairMOT网络等。然而,更加往前一点的基于DeepSORT的方式,即检测与特征提取分开的方式,这一类方式虽然会有累积误差的出现,但也能解决一些实际问题,因此,有必要研究一下这一类网络的操作流程。该篇博客以YOLOv5作为DeepSORT模型的Detections部分。
解决方法
YOLOv5和DeepSORT是分开训练的。因此,针对自己的数据集需要分别训练两个模型,一个基于YOLOv5(V5.0版本,其他版本需要自己调整)的检测模型,一个基于DeepSORT的跟踪模型。以下是整个项目的参考链接。
- 基于DarkLabel2.4自制目标检测数据集
- Yolov5和DeepSORT的数据集处理和训练
xml数据集转换为跟踪数据集
目标跟踪部分训练类别修改
这一步很重要,之前因为没将默认的类别751改为自己的类别而出错 - 代码参考链接
整个训练的框架参考(YOLOv5+DeepSORT)
YOLOv5 v5.0框架,这里也有其他YOLO系列版本的尝试,可以自行选择尝试。 - DeepSORT算法理论研究
- 评价指标参考
具体实现步骤
- 训练YOLOv5模型
这一步参考该链接即可:https://github.com/spacewalk01/yolov5-fire-detection - 训练自制数据集DeepSORT模型
这一步主要参考解决方法中的第2步,处理好数据集的格式。以下为相关代码:
(1)因为我的数据集含有中文路径,因此需要在整个xml文件中添加相关头约束,并重写相关信息。
import os
def add_xml_declaration(xml_folder):
# 获取目录中的所有文件
xml_files = [file for file in os.listdir(xml_folder) if file.endswith(".xml")]
for xml_file in xml_files:
xml_path = os.path.join(xml_folder, xml_file)
# 读取XML文件内容
with open(xml_path, "r", encoding="ISO-8859-1") as f: # 使用 utf-8-sig 编码
xml_content = f.read()
# 检查XML文件是否已经包含XML声明
if not xml_content.startswith('<?xml version="1.0" encoding="UTF-8"?>'):
# 如果没有XML声明,则在内容最前面添加XML声明
xml_content = '<?xml version="1.0" encoding="UTF-8"?>\n' + xml_content
# 将修改后的内容写回XML文件
with open(xml_path, "w", encoding="utf-8") as f: # 使用 utf-8-sig 编码
f.write(xml_content)
if __name__ == "__main__":
xml_folder_path = "./yolo_tracking-3.0/datasets/labels" # 替换为包含XML文件的目录路径
add_xml_declaration(xml_folder_path)(2)提取数据集目标部分
# -*- coding: utf-8 -*-
import cv2
import lxml.etree as ET
import numpy as np
import os
import argparse
import xml.dom.minidom
def main():
# JPG文件的地址
img_path = './yolo_tracking-3.0/datasets/images/'
# XML文件的地址
anno_path = "./yolo_tracking-3.0/datasets/labels/"
# 存结果的文件夹
cut_path = ".yolo_tracking-3.0/datasets/crops/"
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
#print(imagelist)
for image in imagelist:
image_pre, ext = os.path.splitext(image)
#print(image_pre)
img_file = img_path + image
#print(img_file)
img = cv2.imread(img_file)
print (img.shape)
xml_file = anno_path + image_pre + '.xml'
#print (xml_file)
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
# tree = ET.parse(xml_file)
# root = tree.getroot()
# 创建一个自定义解析器,并指定使用支持中文编码的解析器
parser = ET.XMLParser(encoding="utf-8")
# 使用自定义解析器解析XML文件
tree = ET.parse(xml_file, parser=parser)
# 继续对解析后的XML进行操作
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
print(obj_i)
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("&&&&")
if __name__ == '__main__':
main()(3)对以上裁剪得到的数据集根据每个视频/种类进行分类
import os
from PIL import Image
from shutil import copyfile, copytree, rmtree, move
PATH_DATASET = "./yolo_tracking-3.0/datasets/crops/" # 需要处理的文件夹
PATH_NEW_DATASET = "./yolo_tracking-3.0/datasets/after_crops" # 处理后的文件夹
PATH_ALL_IMAGES = PATH_NEW_DATASET + '/all_images'
PATH_TRAIN = PATH_NEW_DATASET + '/train'
PATH_TEST = PATH_NEW_DATASET + '/test'
# 定义创建目录函数
def mymkdir(path):
path = path.strip() # 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在
if not isExists:
os.makedirs(path) # 如果不存在则创建目录
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = PATH_DATASET # 表示需要命名处理的文件夹
# 修改图像尺寸
def resize(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 修改图片尺寸到128宽*256高
im = Image.open(src)
out = im.resize((128, 256), Image.ANTIALIAS) # resize image with high-quality
out.save(src) # 原路径保存
def rename(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 根据图片名创建图片目录
dirname = str(item.split('_')[0])
# 为相同车辆创建目录
# new_dir = os.path.join(self.path, '..', 'bbox_all', dirname)
new_dir = os.path.join(PATH_ALL_IMAGES, dirname)
if not os.path.isdir(new_dir):
mymkdir(new_dir)
# 获得new_dir中的图片数
num_pic = len(os.listdir(new_dir))
dst = os.path.join(os.path.abspath(new_dir),
dirname + 'C1T0001F' + str(num_pic + 1) + '.jpg')
# 处理后的格式也为jpg格式的,当然这里可以改成png格式 C1T0001F见mars.py filenames 相机ID,跟踪指数
# dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
copyfile(src, dst) # os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
def split(self):
# ---------------------------------------
# train_test
images_path = PATH_ALL_IMAGES
train_save_path = PATH_TRAIN
test_save_path = PATH_TEST
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(test_save_path)
for _, dirs, _ in os.walk(images_path, topdown=True):
for i, dir in enumerate(dirs):
for root, _, files in os.walk(images_path + '/' + dir, topdown=True):
for j, file in enumerate(files):
if (j == 0): # test dataset;每个车辆的第一幅图片
print("序号:%s 文件夹: %s 图片:%s 归为测试集" % (i + 1, root, file))
src_path = root + '/' + file
dst_dir = test_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
else:
src_path = root + '/' + file
dst_dir = train_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
rmtree(PATH_ALL_IMAGES)
if __name__ == '__main__':
demo = BatchRename()
demo.resize()
demo.rename()
demo.split()
- 运行解决方法中的第三步整个训练的框架参考(YOLOv5+DeepSORT)中的demo.py文件,实现完整的目标跟踪。其中,根据项目需要,我们做了相应的小改动,具体如下,增加了保存跟踪结果的txt文本。当然,相应的其他代码几个部分需要做微小调动。后续将上传完整代码。
from AIDetector_pytorch import Detector
import imutils
import cv2
import os
def _xyxy_to_tlwh(bbox_xyxy):
x1, y1, x2, y2 = bbox_xyxy
t = x1
l = y1
w = int(x2-x1)
h = int(y2-y1)
return t, l, w, h
def main():
name = 'demo'
det = Detector()
input_video = './Yolov5-Deepsort-main/yolov5-5.0/val_video/hs.mp4'
file_path = "./Yolov5-Deepsort-main/pre_hs_yolov5s.txt"
cap = cv2.VideoCapture(input_video)
name_out = os.path.basename(input_video)
fps = int(cap.get(5))
print('fps:', fps)
t = int(1000/fps)
videoWriter = None
while True:
# try:
flag, im = cap.read()
if im is None:
break
result_ = det.feedCap(im) ##utils/BaseDetector.py
if flag:
pos_frame = int(cap.get(1))
print ('当前处理帧:',pos_frame)
content = result_['frame_cot']
with open(file_path, 'a+') as f:
if len(content):
for item in content:
item_out = _xyxy_to_tlwh(item[:4])
line = '{frame},{id},{x1},{y1},{w},{h},1,-1,-1,-1\n'.format(frame=pos_frame, id=item[5], x1=item_out[0], y1=item_out[1], w=item_out[2], h=item_out[3])
#print (line)
f.write(line)
result = result_['frame']
result = imutils.resize(result, height=640) ###原500
if videoWriter is None:
fourcc = cv2.VideoWriter_fourcc(
'm', 'p', '4', 'v') # opencv3.0
videoWriter = cv2.VideoWriter(
'./results/{}'.format(name_out), fourcc, fps, (result.shape[1], result.shape[0]))
videoWriter.write(result)
#cv2.imshow(name, result)
#cv2.waitKey(t)
#if cv2.getWindowProperty(name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
# break
# except Exception as e:
# print(e)
# break
cap.release()
videoWriter.release()
#cv2.destroyAllWindows()
if __name__ == '__main__':
main()
文章评论