摘要:三维建筑模型在城市规划和智慧城市等众多应用中发挥着至关重要的作用。最近的三维建筑建模方法要么严重依赖于可用的手动收集的足迹参考,要么很难达到与手动编辑相当的真正自动化。为了在细节1级(LoD1)上实现实例级三维建筑的自动提取,我们引入了一种创新的端到端三维建筑实例分割模型。该模型利用正射校正高分辨率遥感图像和数字表面模型(DSMs)同时预测单个建筑物的精确轮廓和高度,消除了额外的参考数据和经验参数设置。首先,我们提出了一个适合于提取二维建筑轮廓的锚定多头(AFM)建筑提取网络。AFM结合了全分辨率、远程相关增强的全局掩模预测分支以及无锚约束盒生成,以及新开发的基于不确定性分析的在线硬样本挖掘(OHSM)训练程序,以强调定位建筑物轮廓时容易出错的位置。随后,我们在AFM中加入高度预测组件,以获得准确的建筑高度信息,从而创建了综合的三维建筑提取模型,称为AFM- 3d。两个阶段的AFM-3D首先预测3-D立方体方案,然后为每个方案生成精细的3-D棱柱模型(LoD1模型)。在不同数据集上的实验证明了AFM和AFM- 3d的优越性能。与最近的方法相比,城市三维数据集的质量分数显著提高了6.4%。除了提出的新方法外,我们还比较了基于锚点和无锚点的遥感数据边界盒生成机制,探索了基于像素和基于轮廓的分割策略,评估了基于学习和经验的高度估计方法,并讨论了DSM数据在三维建筑实例提取中的不可或缺性。这些分析产生了有价值的见解,有助于三维建筑提取研究的进展。
论文介绍
题目:3-D Building Instance Extraction From High-Resolution Remote Sensing Images and DSM With an End-to-End Deep Neural Network
期刊:IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING,
论文:10.1109/TGRS.2024.3383432
年份:2024
创新点
-
1)提出了一种新的端到端LoD1建筑提取模型AFM-3D,该模型利用正射影像和DSM数据预测建筑实例的轮廓和高度。我们的方法引入了一个新的类别掩码预测头来生成高分辨率和远程相关增强分割图,与以前的方法相比,提高了二维轮廓生成的精度。
-
2)为了提高构建实例分割的准确性,特别是在具有挑战性的边缘区域,我们在训练过程中实现了在线硬样本挖掘(OHSM)策略。
-
3)此外,我们的贡献包括比较单独使用正射影像和结合DSM数据作为输入的使用,探索生成边界框的最佳方法,评估不同的建筑实例分割方法,以及研究传统和DL方法用于建筑高度估计。
研究背景
(1)探讨了基于锚框和无锚框的边界框生成机制在遥感数据建筑物实例分割中的适应性,并比较了基于像素和基于轮廓的分割策略。
(2)评估了基于学习的和基于经验的建筑物高度估计方法,并强调了DSM数据在3D建筑物实例提取中的重要性。
A. 2-D Building Instance Segmentation
Pixel-segmentation-based:基于像素分割的方法进行逐像素分类分配,以找到每个实例的覆盖区域.
Contour-regression-based:基于轮廓回归的方法不同于这些基于像素的分割技术,后者将建筑实例分割挑战视为轮廓回归任务[37],[38],[39]。以轮廓为中心的方法消除了光栅到矢量转换的必要性,而是直接获取矢量化的建筑轮廓。
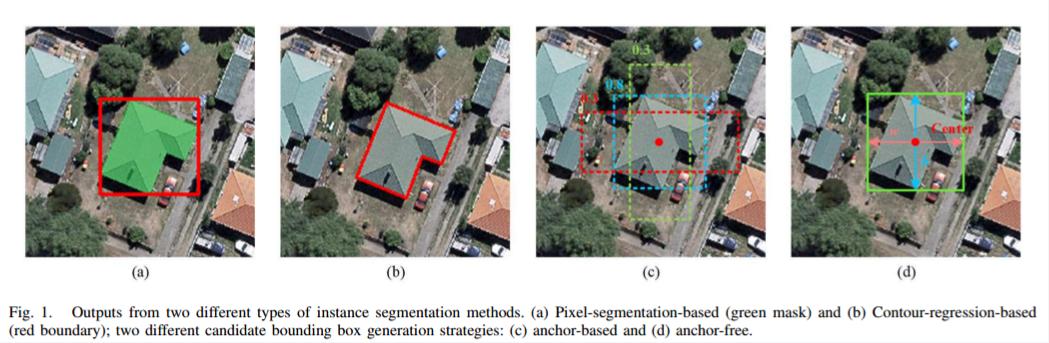
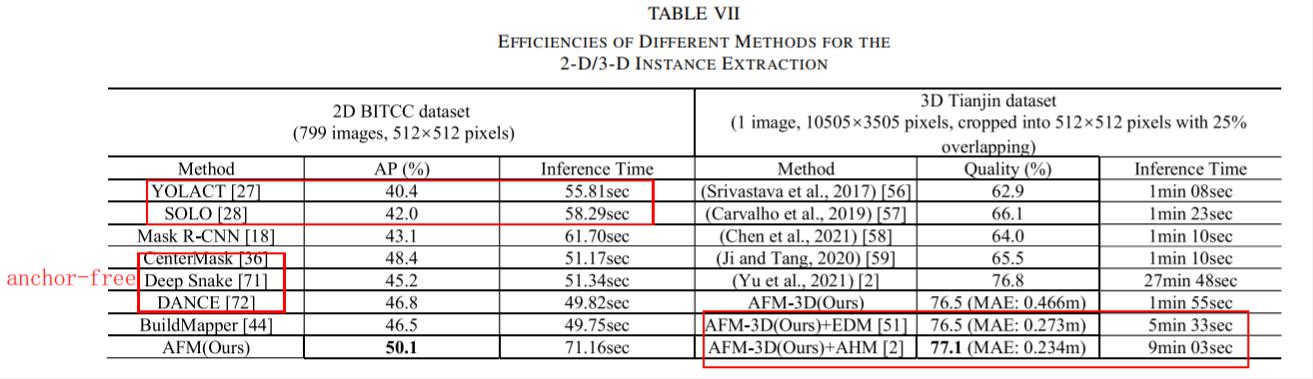
相比锚点方法,锚点自由方法有什么优势?
锚点自由方法能更好地适应不同尺度的建筑物实例。Mask R-CNN等采用锚点方法的方法在提取不同尺度建筑物实例方面表现较差,而采用锚点自由策略的CenterMask和AFM方法表现更优。
锚点自由方法能更好地适应复杂的遥感图像背景。复杂背景和模糊边界会影响基于轮廓回归的方法(如Deep Snake和DANCE)的精度,而像素分割的CenterMask和AFM方法更能适应这种情况。
B. 3-D Building Instance Extraction
本文主要关注LoD1模型,它是一种水密模型,具有平顶屋顶和足迹轮廓。在通过二维实例分割获得正射影像中的建筑轮廓后,根据高度值将屋顶平面挤压到地平面,生成三维建筑实例(称为LoD1模型)就成为一个简单的过程[47],[48]。
数据
1) 2-D Building Datasets:
(1) WHU building dataset: aerial images;0.2m分辨率;512×512size;
【Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery dataset】
(2)BITCC dataset:Google Earth satellite images;0.29m分辨率;500×500size;
【A dataset of building instances of typical cities in China】
2) 3-D Building Instance Datasets:
(1) Tianjin dataset:正射影像、DSM与对应的LoD1建筑物标签;地面样本距离(GSD)0.1m(作者降采样到0.2m);
【Automatic 3D building reconstruction from multi-view aerial images with deep learning】
(2)Urban 3-D challenge dataset:正射影像;GSD为0.5m;2048×2048size
【Urban 3D challenge: Building footprint detection using orthorectified imagery and digital surface models from commercial satellites】
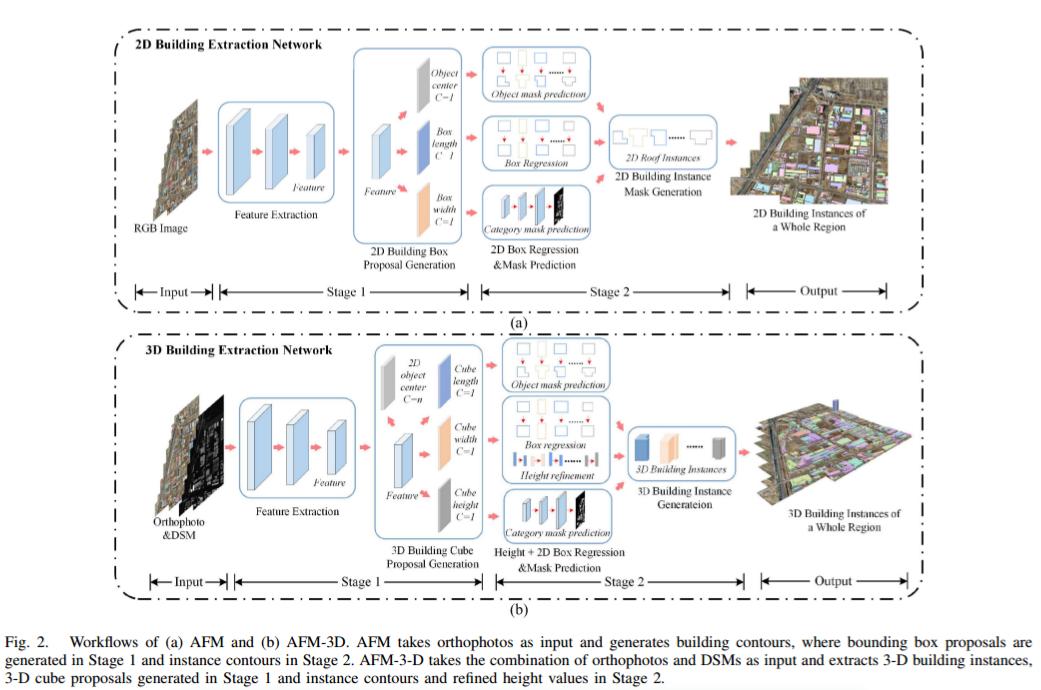
方法
总体结构
提出了一个端到端网络,可以预测单个建筑的轮廓和各自的高度。预测屋顶轮廓的部分称为无锚多头(AFM)建筑物提取网络,它是三维建筑物提取模型的基础。在此基础上,在AFM上引入了一个新的分支来预测建筑高度,从而实现了一个全面的端到端三维建筑提取解决方案,命名为AFM- 3d。
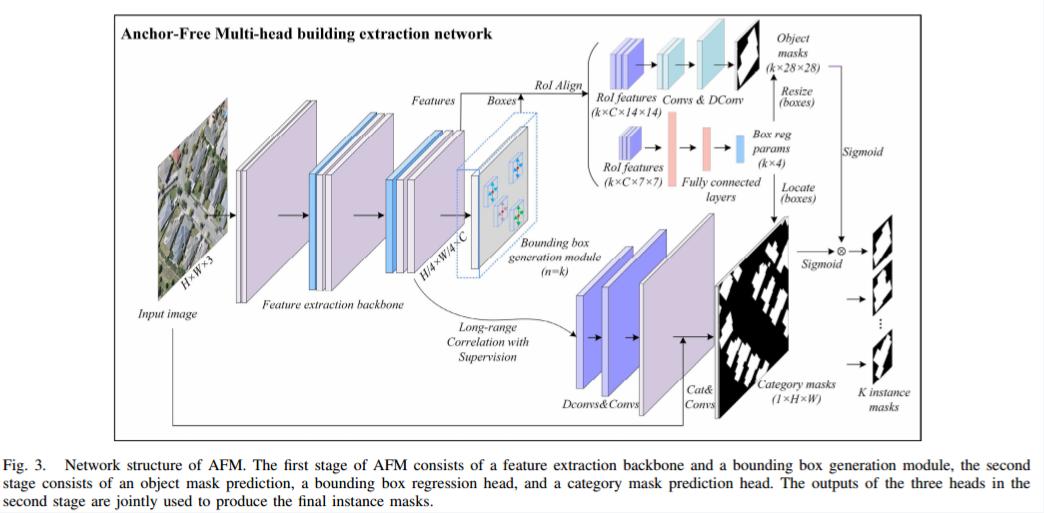
AFM用于建筑物实例轮廓提取
AFM是一种用于提取2D建筑物轮廓的深度学习网络,它采用了两阶段的网络结构。
第一阶段使用了一种无锚框的边界框生成机制,可以灵活地捕捉不同大小的建筑物边界框。
第二阶段包含三个并行的头部:目标掩膜预测头、边界框回归头和类别掩膜预测头,协同产生最终的建筑物实例掩膜。
作者还提出了一种在线困难样本挖掘(OHSM)的训练策略,以提高边缘像素的分割质量。
AFM的first stage
这里解释了为何选用anchor-free的方法:
基于锚点的方法假设目标可以重叠,这通常不适用于遥感目标检测场景。此外,它还预定义了一组固定大小的边界框。这是有问题的,因为密集的固定尺寸锚盒不仅难以适应各种建筑尺寸,而且还会导致正样本和负样本之间的不平衡。相反,本文选择的无锚机制为每个建筑生成一个候选框。此外,它直接预测每个盒子的精确尺寸,而不是依赖于预先确定尺寸的模板。因此,无锚方法在灵活捕获不同建筑尺寸的候选框方面表现出色,同时最大限度地减少冗余框的产生。具体来说,锚定边界框生成模块预测建筑物的中心、长度、宽度和偏移量(舍入误差)。具有最高k置信度分数的预测中心,以及它们相应的大小和偏移量,共同代表候选建筑边界框。关于无锚机构的更多细节,请参考[45]。
【A new spatial-oriented object detection framework for remote sensing images】
AFM的second stage
-
Object Mask Prediction Head:
从第一阶段生成的候选框中,预测每个候选框的分类无关的单通道目标掩膜。
通过一系列卷积和转置卷积层,预测出28×28像素大小的目标掩膜。每个像素值表示该像素属于对应候选目标的概率。
在训练时,目标掩膜头的损失函数包括二进制交叉熵损失和Dice损失。 -
Bounding Box Regression Head:
利用低分辨率的RoI特征,通过一系列的扁平化和全连接层,预测k个候选框的回归参数,从而提高候选框的位置和大小的精度。
在训练时,边界框头的损失函数包括CIoU损失和Smooth L1损失。
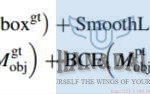
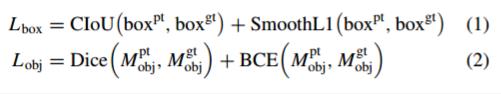
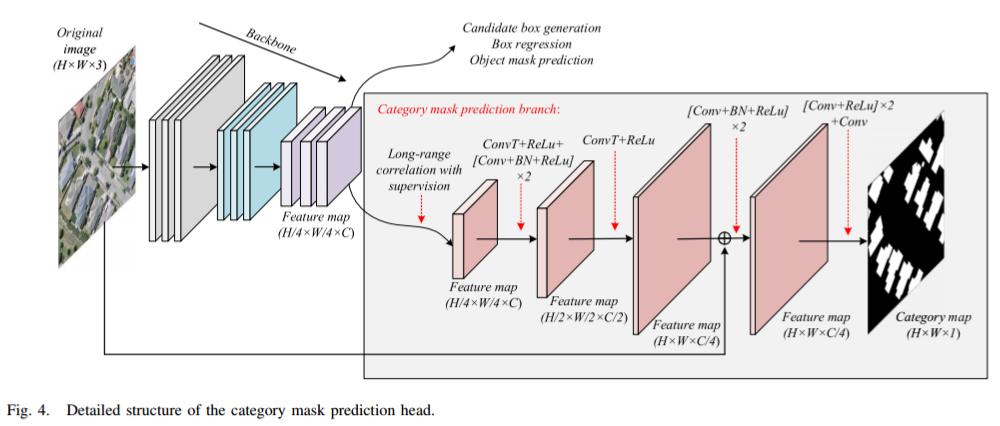
AFM的Category Mask Prediction Head
Category Mask Prediction Head是AFM模型的第三个并行头部,其目的是生成像素级别的建筑物分类掩膜。这个头部的设计是为了解决由于对象掩膜缩放而导致的空间细节丢失问题。
(1)Category Mask Prediction Head使用一个长距离特征相关性监督模块(FCSM)来重新校准4倍下采样的主干特征,以减少属于同一类别(如不同类型的建筑物)的像素之间的特征差异。
(2)在训练过程中,Category Mask Prediction Head同样使用BCE和Dice损失进行监督。
AFM的Instance Mask Generation and OHSM
Instance Mask Generation and OHSM是AFM模型的最后一步,通过融合对象掩膜和分类掩膜以及基于不确定性的OHSM策略,进一步提高了建筑物实例分割的精度。
AFM将上采样的对象掩膜(Mobj)与裁剪的分类掩膜(Mcat,代表全分辨率分类掩膜中的对象区域)进行融合,通过Hadamard积计算得到实例掩膜(Mins)。在训练过程中,这个融合的实例掩膜同样接受二元交叉熵损失和Dice损失的监督。
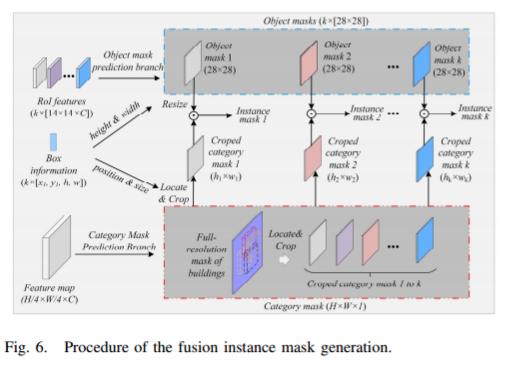
尽管引入了全分辨率的分类掩膜有助于缓解由于对象掩膜缩放而导致的边界模糊问题,但仍可能存在一些不确定区域影响精确的建筑物边界定位。
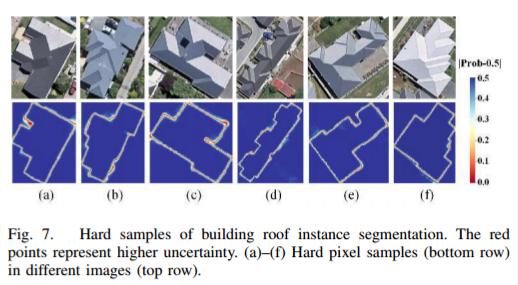
为了进一步解决边界模糊的问题,AFM提出了一种基于不确定性分析的OHSM策略。
OHSM首先根据融合实例掩膜中像素的不确定性进行排序,选择最高不确定性的1/8像素作为困难样本。
在计算实例掩膜预测损失时,将这些困难样本的权重系数加倍,从而使网络更关注这些边界区域。
通过迭代更新困难样本、计算加权损失以及优化网络参数,AFM可以提高对建筑物边界的识别能力,而无需增加太多计算开销。
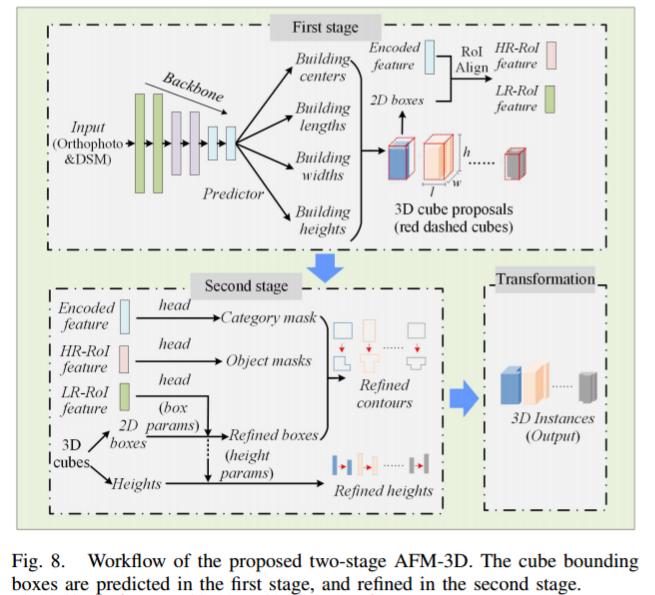
AFM-3D用于建筑物重建
AFM-3D 的关键阶段包括以下几个方面:
(1)第一阶段预测初步的 3D 建筑物包围盒(长、宽、高)。这是通过预测建筑物中心点位置并基于这些中心点生成 3D 立方体提议来实现的。
(2)第二阶段对初步预测的高度值进行细化。这是通过利用低分辨率的 RoI 特征,并引入两个全连接层来预测高度缩放因子,从而优化高度回归的目标函数。同时在第二阶段,也进行了与 AFM 相同的 2D 建筑物轮廓细化过程。
(3)最后将预测的 2D 轮廓和高度值结合 DSM 数据,转换为 LoD1 格式的 3D 建筑物实例。
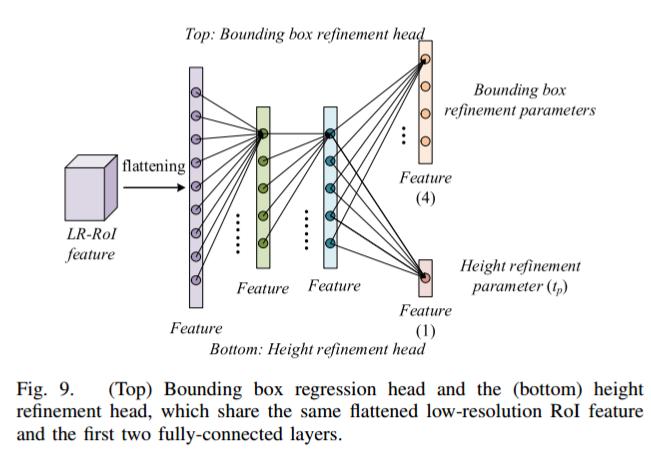
AFM-3D 模型中预测的高度值细化过程如下:
在第二阶段,使用低分辨率的 7 × 7 RoI 特征来对最初估计的高度值进行细化。
高度细化头包括两个全连接层,与边界框回归头共享。同时还引入了一个独立的全连接层来估计高度参数 。
高度细化的目标函数是 Tg = Hg/Hp,其中 Hg 表示地面实际高度,Hp 表示第一阶段预测的高度。通过回归一个缩放因子而不是绝对高度修正值(Hg - Hp),可以简化学习过程。
使用 L1 损失函数来优化高度回归参数。只有那些 2D 边界框 IoU 得分超过 50% 的候选框才会参与细化过程。
通过这种方式,AFM-3D 模型能够有效地对初步预测的建筑物高度进行细化和优化,提高最终 3D 建筑物提取的准确性 。
精度
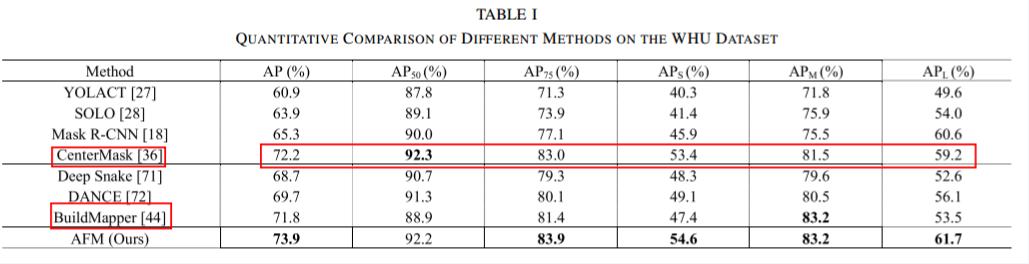
(1)2-D Building Instance Segmentation Results
在WHU上的结果:
在BITCC上的结果:
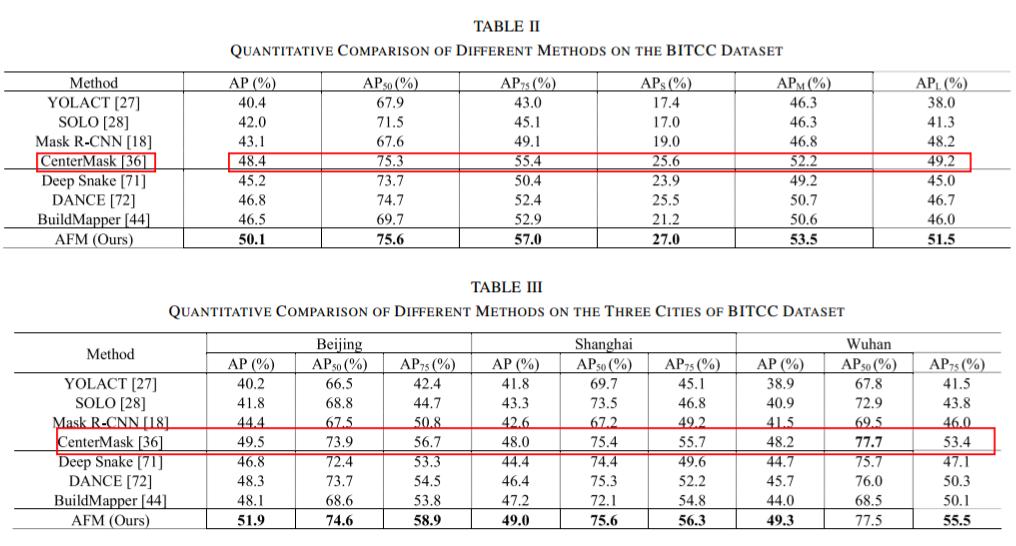
(2)3-D Building Instance Extraction Results
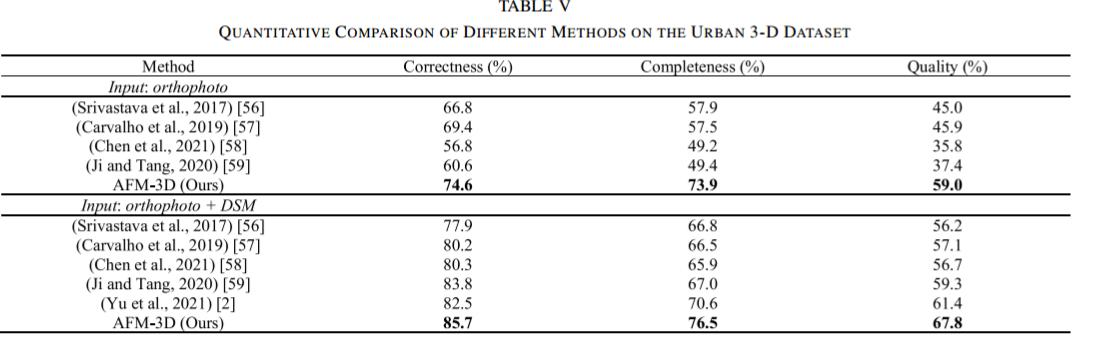
加入DSM后,三维建筑实例提取的性能显著提高,与不使用DSM的结果相比,效果显著提高10%以上。
在Tianjin数据集上的结果:
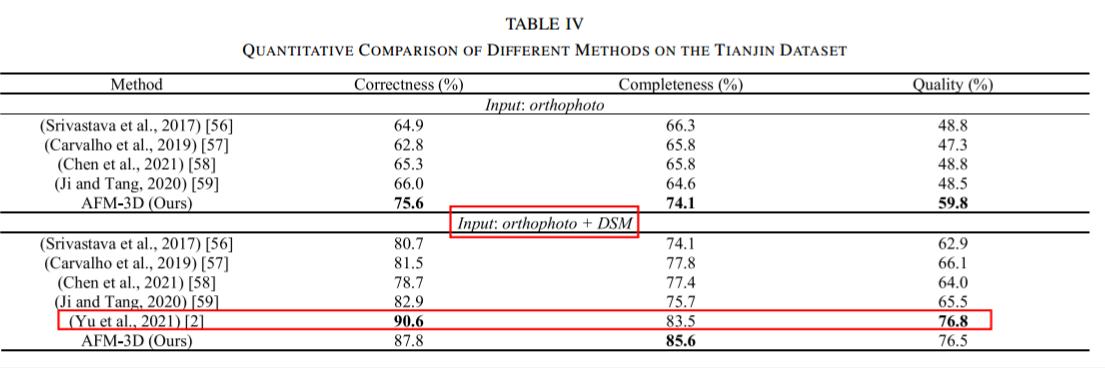
在 Urban 3-D上的结果:
(3)消融实验
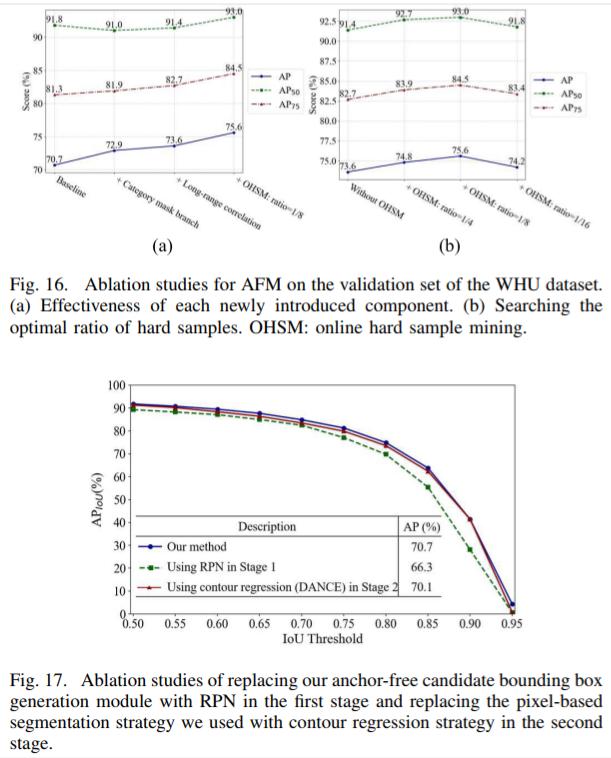
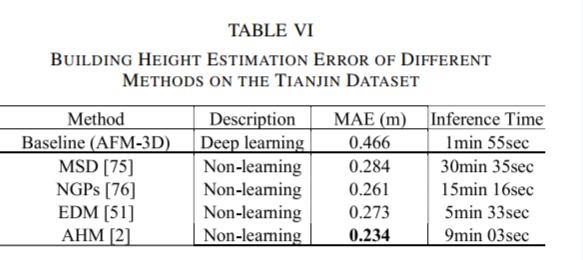
给定数字表面模型(DSM)和预测的单个建筑物边界,建筑物高度估计是一个相对简单的问题,可以通过经验方法解决。
在 AFM-3D 中,建筑物高度是与长度和宽度并行预测的。对于非深度学习方法,建筑物高度可以通过从 DSM 中减去地面高度或数字地形模型(DTM)的高度来估计。
本文研究了两种 DTM 生成方法:多方向和斜率依赖方法(MSD)和地面点网络(NGP)方法。此外,还比较了高程差分模型(EDM)和之前工作中提出的自适应高度测量(AHM)方法。
与深度学习方法相比,非深度学习方法通常更可靠,一致表现出更小的平均绝对误差(MAE)值。在 MSD、NGP、EDM 和 AHM 中,AHM 表现更好,而 EDM 更快。
将 AHM 和 EDM 与 AFM-3D 结合使用可以进一步提高 3D 建筑物模型的提取质量。

文章评论