提出问题
最近在科研中,遇到需要利用mmtracking框架进行多目标跟踪实现自制数据集的应用。因此,简单记录一下数据集制作过程以及利用mmdetection和mmtracking框架结合下的多目标跟踪过程。
解决方案
(1)数据集制作
视频数据集制作利用的软件是DarkLabel 2.4,其链接如下:DarkLabel下载地址,其基本标注方法可参考我上一篇博文,链接如下:DarkLabel2.4软件标注视频影像数据做目标检测/跟踪(数据预处理)。与上一篇博文不同的是,这次我们是以MOT17数据集格式进行数据集制作的,因此,需要进行DarkLabel2.4软件的微调整,具体是调整软件中的darklabel.yml文件,如下所示:
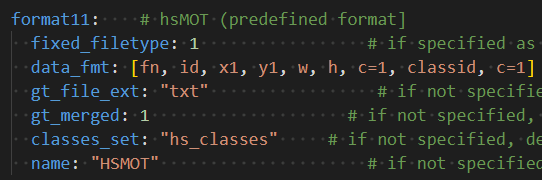
并在该文件的上方加入自己数据集的类别,如:
hs_classes: [ship, airplane, car, fire](2)软硬件基本配置
一张3090显卡,ubuntu 20.04系统,CUDA 11.3;
python 3.9;
pytorch==1.12.1+cu113;
mmcv-full==1.6.2;
mmengine==0.9.0;
yapf==0.40.1;
mmdet==2.24.1;
mmtrack==0.14.0
重要步骤
- 数据集转换
由DarkLable制作的数据集,不能直接作为数据源支持模型训练,需要做数据集转换,这里提供一个数据集转换代码,可转换为coco格式,用于目标检测:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import pickle
import json
import numpy as np
import os
import shutil
import cv2
HAVE_DET_FILE = False
HALF_VIDEO = False
CREATE_SPLITTED_ANN = False
CREATE_SPLITTED_DET = False
def convert_airmot(data_p='/workspace/JLTrack/', SPLITS=None, HALF_VIDEO=False):
"""
Convert dataset annotations from text files to COCO format JSON files.
Parameters:
data_p (str): Base path to the dataset.
SPLITS (list): List of dataset splits to process (e.g., ['train', 'test']).
HALF_VIDEO (bool): Whether to process only half of the video frames.
"""
if SPLITS is None:
SPLITS = ['train', 'test']
OUT_PATH = os.path.join(data_p, 'annotations')
if not os.path.exists(OUT_PATH):
os.mkdir(OUT_PATH)
for split in SPLITS:
data_path = os.path.join(data_p, split if not HALF_VIDEO else 'train')
out_path = os.path.join(OUT_PATH, f'{split}.json')
out = {
'images': [],
'annotations': [],
'categories': [
{'id': 0, 'name': 'ship'},
{'id': 1, 'name': 'drone'},
{'id': 2, 'name': 'vehicle'},
{'id': 3, 'name': 'smoke&fire'}
],
'videos': []
}
seqs = sorted(os.listdir(data_path))
image_cnt = 0
ann_cnt = 0
video_cnt = 0
for seq in seqs:
if '.DS_Store' in seq:
continue
video_cnt += 1
out['videos'].append({'id': video_cnt, 'file_name': seq, 'name': seq})
seq_path = os.path.join(data_path, seq)
img_path = os.path.join(seq_path, 'img')
#ann_path = os.path.join(seq_path, 'gt', f'{seq}.txt')
ann_path = os.path.join(seq_path, 'gt', 'gt.txt')
images = os.listdir(img_path)
current_img = cv2.imread(os.path.join(img_path, '000000.jpg'))
height, width, _ = current_img.shape
num_images = len([image for image in images if 'jpg' in image])
if HALF_VIDEO and ('half' in split):
image_range = [0, num_images // 2] if 'train' in split else [num_images // 2 + 1, num_images - 1]
else:
image_range = [0, num_images - 1]
for i in range(num_images):
if i < image_range[0] or i > image_range[1]:
continue
image_info = {
'file_name': f'{seq}/img/{i:06d}.jpg',
'height': height,
'width': width,
'id': image_cnt + i,
'frame_id': i - image_range[0],
'prev_image_id': image_cnt + i if i > 0 else -1,
'next_image_id': image_cnt + i + 2 if i < num_images - 1 else -1,
'video_id': video_cnt
}
out['images'].append(image_info)
print(f'{seq}: {num_images} images')
anns = np.loadtxt(ann_path, dtype=np.float32, delimiter=',')
for i in range(anns.shape[0]):
frame_id = int(anns[i][0])
if frame_id - 1 < image_range[0] or frame_id - 1 > image_range[1]:
continue
track_id = int(anns[i][1]) + 1
if track_id < 1:
print(seq)
print(int(anns[i][0]))
cat_id = int(anns[i][7])
print('cat_id', cat_id)
ann_cnt += 1
ann = {
'id': ann_cnt - 1,
'category_id': cat_id,
'image_id': image_cnt + frame_id,
'track_id': track_id,
'bbox': anns[i][2:6].tolist(),
'area': int(anns[i][4] * anns[i][5]),
'conf': 1.0,
'iscrowd': 0,
'ignore': 0
}
out['annotations'].append(ann)
print(f' {int(anns[:, 0].max())} ann images')
image_cnt += num_images
print(f'loaded {split} for {len(out["images"])} images and {len(out["annotations"])} samples')
json.dump(out, open(out_path, 'w'))
if __name__ == '__main__':
convert_airmot(data_p ='./video/HS_exe/datasets/')转换后的数据集可以用于检测,但针对多目标跟踪仍存在一些问题,因此,需要构建seqinfo.ini数据集介绍文件,其代码如下:
import os
import configparser
from PIL import Image
def create_seqinfo_ini(path, name, im_dir, frame_rate, seq_length, im_width, im_height, im_ext):
config = configparser.ConfigParser()
config['Sequence'] = {
'name': name,
'imDir': im_dir,
'frameRate': frame_rate,
'seqLength': seq_length,
'imWidth': im_width,
'imHeight': im_height,
'imExt': im_ext,
}
with open(os.path.join(path, 'seqinfo.ini'), 'w') as configfile:
config.write(configfile)
def process_directory(base_path, parent_folder_name):
for root, dirs, files in os.walk(base_path):
if 'img' in dirs and 'gt' in dirs:
img_dir = os.path.join(root, 'img')
img_files = [f for f in os.listdir(img_dir) if f.endswith('.jpg')]
if img_files:
first_img_path = os.path.join(img_dir, img_files[0])
with Image.open(first_img_path) as img:
im_width, im_height = img.size
seq_length = len(img_files)
create_seqinfo_ini(root, parent_folder_name, 'img', 30, seq_length, im_width, im_height, '.jpg')
def main():
base_path = 'train_test_split' # 替换为你的实际路径
for folder in ['train', 'test']:
folder_path = os.path.join(base_path, folder)
for subfolder in os.listdir(folder_path):
subfolder_path = os.path.join(folder_path, subfolder)
if os.path.isdir(subfolder_path):
process_directory(subfolder_path, subfolder)
if __name__ == '__main__':
main()
同时,在mmtracking框架中,帧序号不能从0开始,而DarkLable是从0编号的,因此,需要进行第一列修改,其代码如下。该代码同时将gt文件夹下的以文件夹命名的.txt文件,统一改为了gt.txt,要不然目标跟踪训练时测试阶段不能做评价指标计算。
import os
def process_txt_file(file_path):
# 读取文件内容
with open(file_path, 'r') as file:
lines = file.readlines()
# 修改第一列数字并写回文件
with open(file_path, 'w') as file:
for line in lines:
parts = line.strip().split(',')
parts[0] = str(int(parts[0]) + 1)
file.write(','.join(parts) + '\n')
def rename_and_process_files(base_dir):
# 遍历train和test文件夹
for folder in ['train', 'test']:
folder_path = os.path.join(base_dir, folder)
for subdir in os.listdir(folder_path):
subdir_path = os.path.join(folder_path, subdir)
if os.path.isdir(subdir_path):
gt_folder_path = os.path.join(subdir_path, 'gt')
if os.path.exists(gt_folder_path):
for file_name in os.listdir(gt_folder_path):
if file_name.endswith('.txt') and file_name != 'gt.txt':
old_file_path = os.path.join(gt_folder_path, file_name)
new_file_path = os.path.join(gt_folder_path, 'gt.txt')
os.rename(old_file_path, new_file_path)
process_txt_file(new_file_path)
# 设置train_test_split文件夹的路径
base_dir = './train_test_split_small'
rename_and_process_files(base_dir)
-
多类多目标数据集设计,可参考该链接:多类多目标数据集代码修改
-
在mmtracking的预测阶段,没有直接给出保存跟踪结果的txt或者json文件的接口,我们进行了微修改,可以保存预测结果。如下:
其具体函数在/mmtrack/datasets/mot_challenge_dataset.py文件中可以查找,函数如下:def format_results(self, results, resfile_path=None, metrics=['track']): """Format the results to txts (standard format for MOT Challenge). Args: results (dict(list[ndarray])): Testing results of the dataset. resfile_path (str, optional): Path to save the formatted results. Defaults to None. metrics (list[str], optional): The results of the specific metrics will be formatted.. Defaults to ['track']. Returns: tuple: (resfile_path, resfiles, names, tmp_dir), resfile_path is the path to save the formatted results, resfiles is a dict containing the filepaths, names is a list containing the name of the videos, tmp_dir is the temporal directory created for saving files. """ assert isinstance(results, dict), 'results must be a dict.' if resfile_path is None: tmp_dir = tempfile.TemporaryDirectory() resfile_path = tmp_dir.name else: tmp_dir = None if osp.exists(resfile_path): print_log('remove previous results.', self.logger) import shutil shutil.rmtree(resfile_path) resfiles = dict() for metric in metrics: resfiles[metric] = osp.join(resfile_path, metric) os.makedirs(resfiles[metric], exist_ok=True) inds = [i for i, _ in enumerate(self.data_infos) if _['frame_id'] == 0] num_vids = len(inds) assert num_vids == len(self.vid_ids) inds.append(len(self.data_infos)) vid_infos = self.coco.load_vids(self.vid_ids) names = [_['name'] for _ in vid_infos] for i in range(num_vids): for metric in metrics: formatter = getattr(self, f'format_{metric}_results') formatter(results[f'{metric}_bboxes'][inds[i]:inds[i + 1]], self.data_infos[inds[i]:inds[i + 1]], f'{resfiles[metric]}/{names[i]}.txt') return resfile_path, resfiles, names, tmp_dir最终预测结果保存如下:
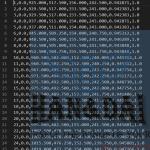

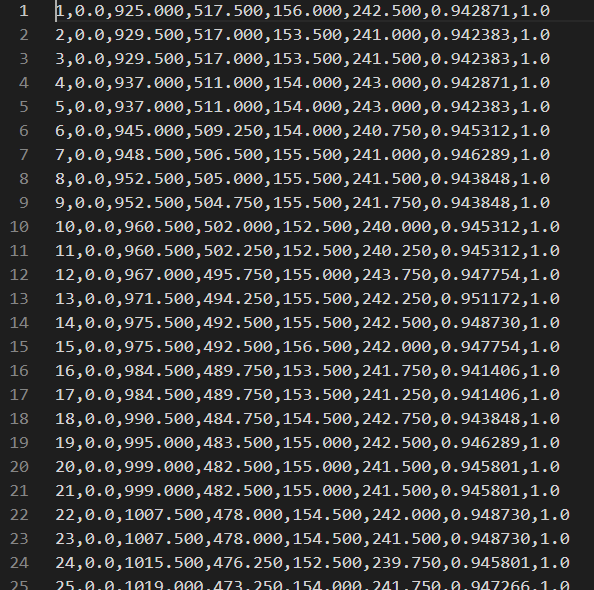
注:这里提供一下mmtracking的中文使用手册地址:mmtracking0.14.0使用手册

文章评论